ビギナーでも読める!AcrobatProでの内部構造参照
はい、ご無沙汰です。もうね、へんなところで忙しくって諸々追いつかないわけです。ということで、皆様に置かれましてはご清祥のこととお慶び申し上げる次第です。はい。
日頃からPDFの構造がどうとかぶつぶつ言っているわけなんですけど、誰かついてきてくれるって事もなくPDFの内部構造について一晩語らうって事も出来そうにないのが現状です。ということで、PDFの内部構造を参照し愛でる会を立ち上げたいと思います。
今回お届けするのはPDFの内部構造を愛でるためのスキル養成の一環として「ビギナーでも読める!AcrobatProでの内部構造参照」と題してお届けいたします。
あっ、会員は随時募集中です。ということで続きをどうぞ。
PDFの構造の実際
まずはPDFファイルの中身を生で見てみます。

このように基本的にAsciiコードとバイナリが混じった状態ですね。Asciiコードで記述された部分は人間が読むことが出来ます。ところどころにAsciiコードではない部分がまじりますが、その部分は数値であったりエンコードされた部分だったりします。
画像などはAscii85にエンコードされるか圧縮されるかしてデータストリームとして記述されます。
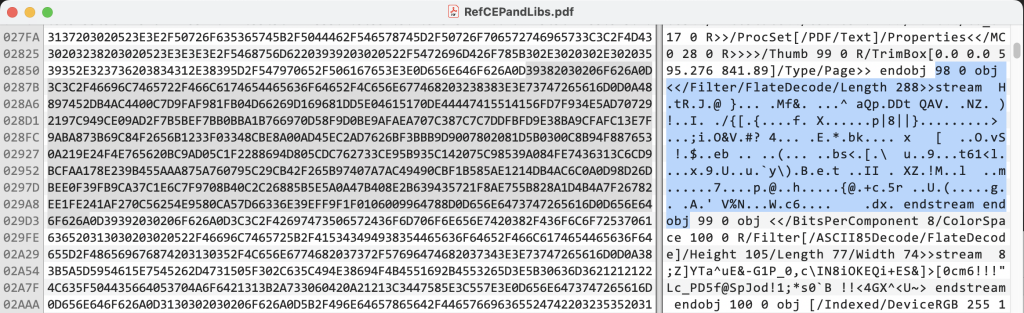
この部分はFlateストリームという圧縮データとして記述されています。もちろん専門の人が見ても中身はわからないので何らかの手段を利用してデコードしないと確認は不能です。
そんなときに重宝するのがAcrobatProさんです。
AcrobatProDCの「PDFの内部構造を参照…」について
AcrobatProさんのプリフライトパネルには開いているドキュメントの内部構造を参照するための機能があります。
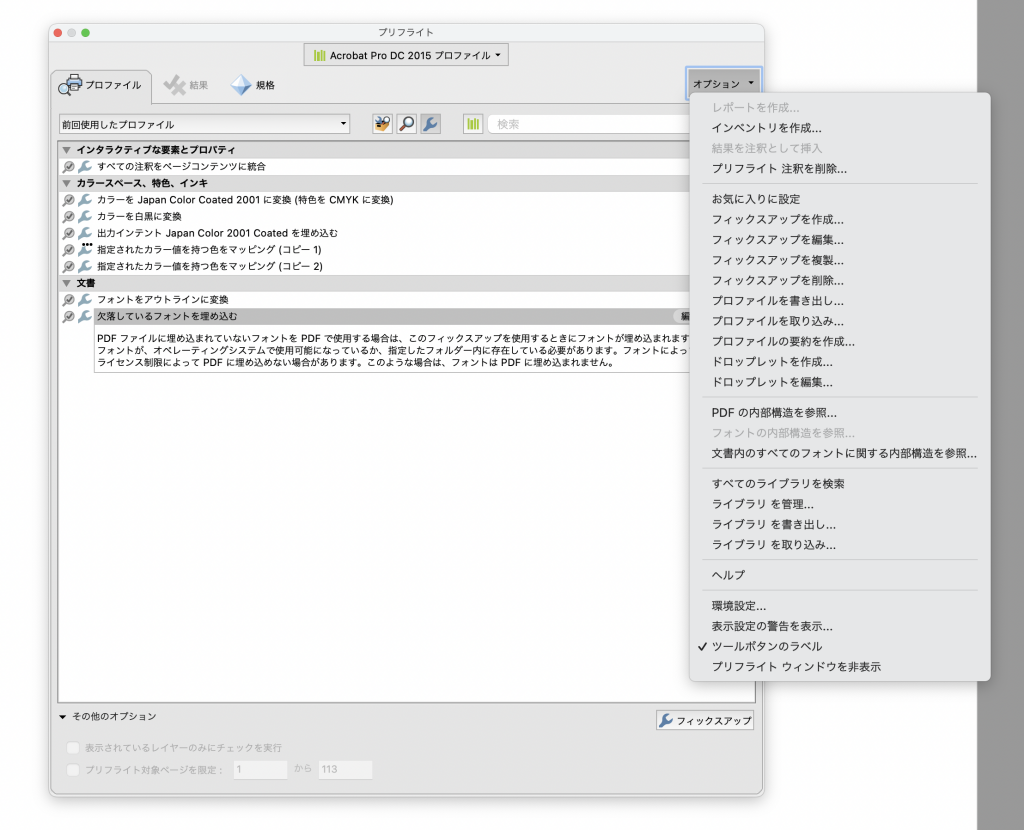
今までも何回か紹介しているんですけど、この機能の使い方を抑えておきましょう。
上の状態がデフォルトです。折りたたまれている部分を展開すると内包する要素が参照できるようになっています。
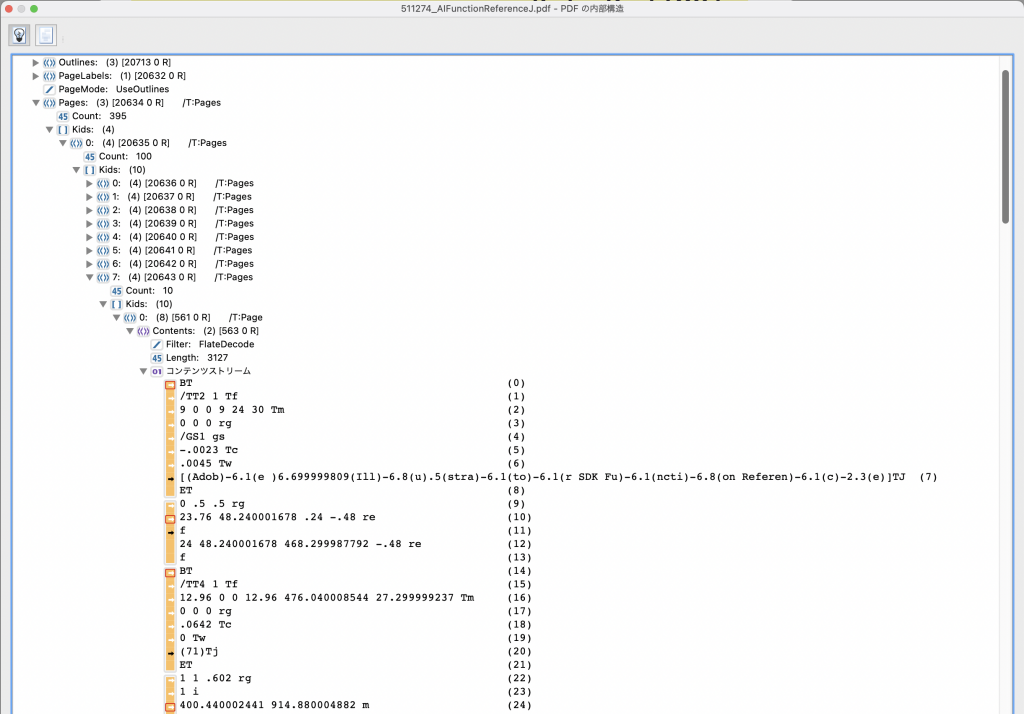
このようにPages以下の子要素をたどると実際のPDFコンテンツの構造にたどり着きます。
個々で表示されているコンテンツはFlateDecodeストリームに収められているものです。先にバイナリエディタで参照した時はバイナリストリームとして表示されていましたが、Acrobatではデコードされて本来のデータ構造として確認できます。
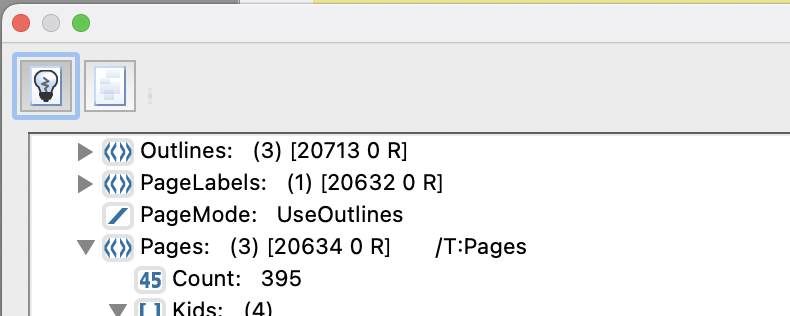
この部分の操作を見ていきましょう。デフォルトでは左側の電球アイコンがアクティブになっています。この状態は「DocumentStructure(書類構造)」を参照している状態です。ドキュメントのデータ構造がストレートにツリー化されている状態です。
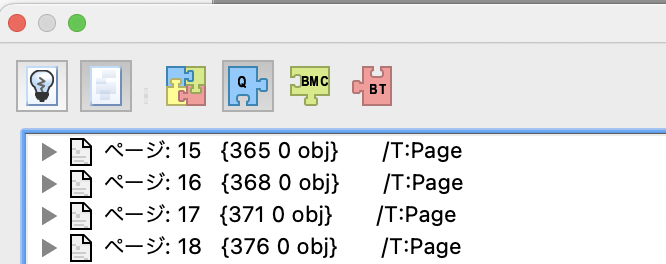
隣の書類アイコンをクリックすると更にボタンが右側に現れます。これは書類構造ではなくPDFドキュメントの「LogicalStructure(論理構造)」を参照するものです。
DocumentStructureとLogicalStructureについて
PDFは編集可能だということは皆様ご存知かと思います。しかし、その編集処理の過程においてどういった事が行われているかという事を詳細に把握されている方はごく少数でしょう。
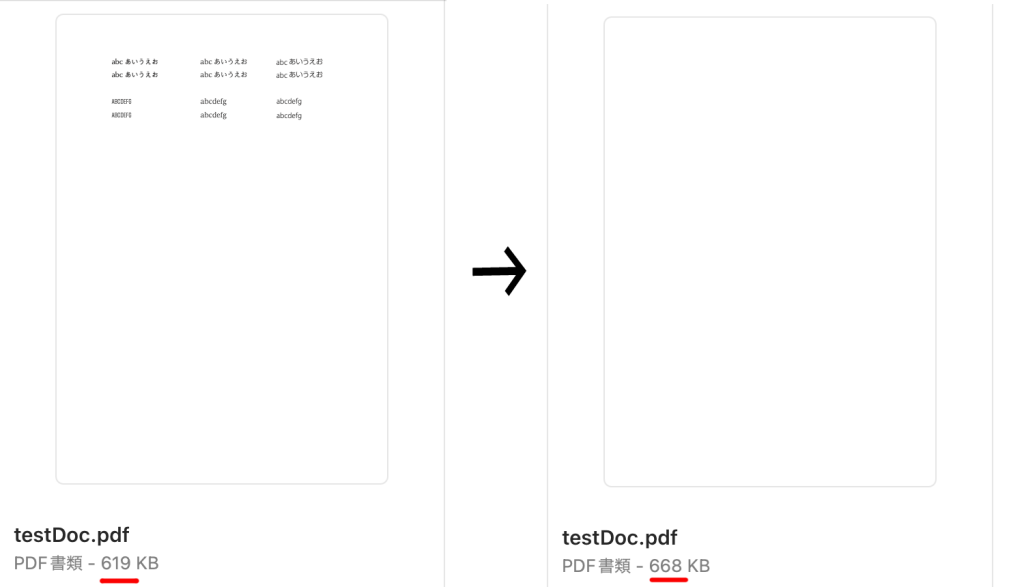
こちらはPDFを編集した前後のファイル容量の変化を示すものです。編集の内容はページコンテンツをすべて選択して削除しただけです。削除したにも関わらずファイル容量が増加しています。
PDFファイルを編集する場合、元のPDFからはデータストリームは削除されません。変更された部分のデータ構造がPDFファイルの末尾に追加されクロスリファレンステーブルの設定を更新し該当部分の参照を新たに追加した部分を参照するように書き換えることによって編集とします。上の例の場合、元のコンテンツへの参照部分を新たにPDF末尾に追加した部分に切り替えるた状態となっています。データを削除した場合でも元の書類構造が保持されたままで、そこに追加された情報(この場合は空白のページ情報)が追加されるのでコンテンツを削除したにも関わらず容量の増加が見られるのです。
ということで、編集を繰り返したPDFドキュメントは頭から見ていくだけでは処理できずあちこち読み込みつつ表示データを生成していくことになります。
Acrobatはこのような場合でもデータ表示に沿ったデータ構造を表示可能です。これがLogicalStructureでクロスリファレンステーブルの記述に沿って並べ直された状態のデータ構造を表示してくれます。
では論理構造のみかたを説明しましょう。
LogicaStructure表示では4つのモードが用意されています。
左端がクラシックと呼ばれるもので、すべてページコンテンツを表示します。
2番めがQとアイコンにあるようにqーQオペレータで定義されるグラフィックに関する論理構造をグループ化して表示します。
3番目はBMCでBMC-EMCで表されるMarkedContentsストリームをソートします。
最後のものがテキストに関するBT-ETオペレータによるストリームをソートします。
各オペレータについての知識がなくても、クラシック表示では下に示すように各オペレータがどのような機能を持つものかの説明が表示されます。

このようにクラシック表示の説明は詳細なものです。PDFの構造を理解するための足掛かりとしては充分なものです。
各オペレータについて詳細な情報は以下のドキュメントをお読みください。
https://opensource.adobe.com/dc-acrobat-sdk-docs/pdfstandards/pdfreference1.7old.pdf