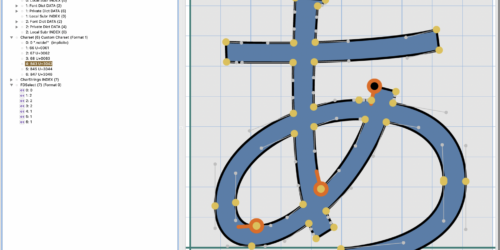
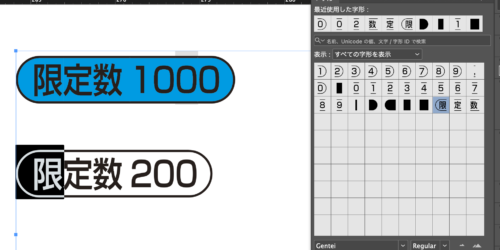
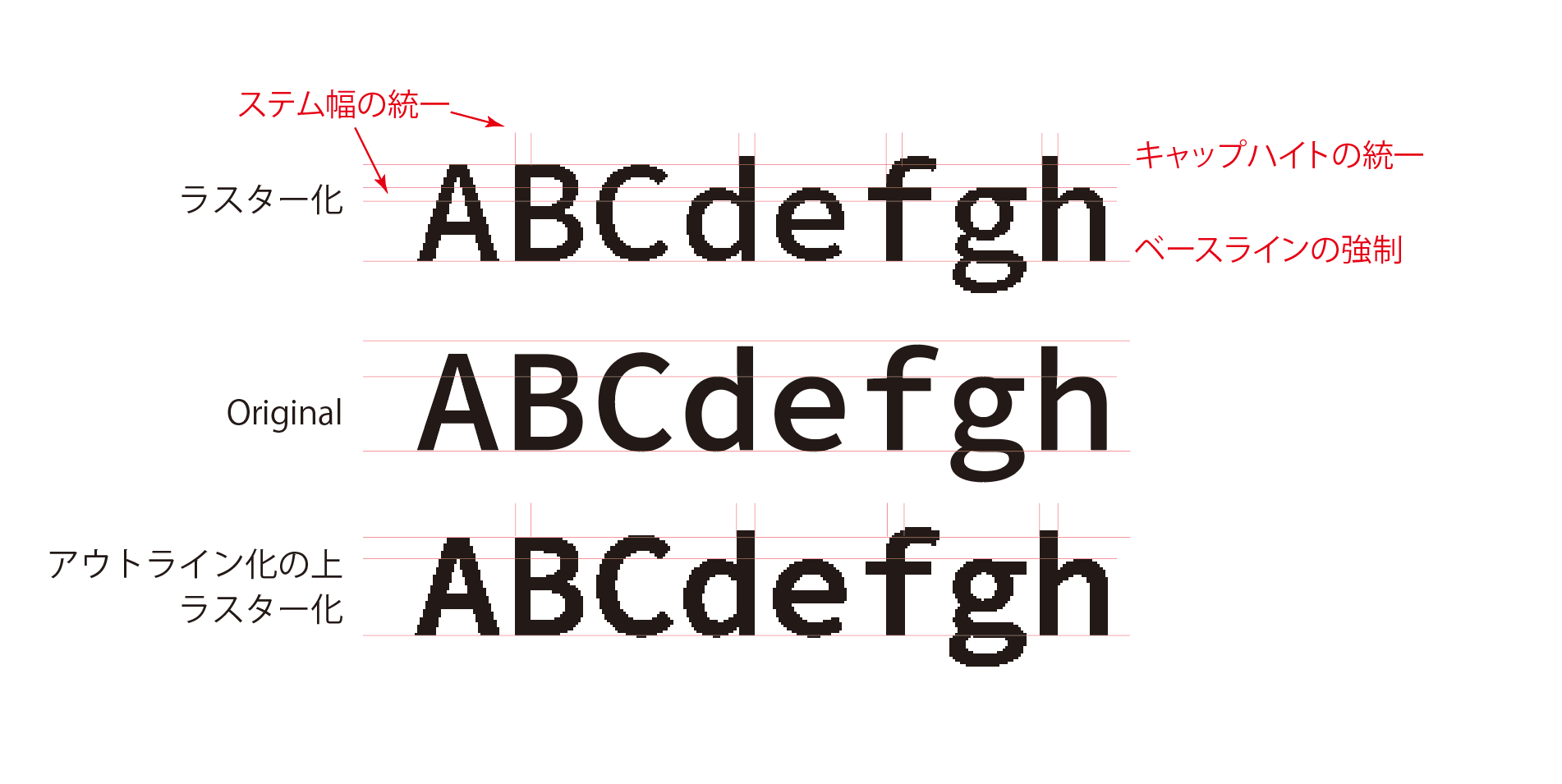2025年7月5日Illustratorでフォントをつくるスクリプトの紹介今年は早々に梅雨があけてしまって連日クソ熱いわけですが、例年であれば、クソ暑い中めちゃくちゃうるさいセミがまだ鳴いていな... カテゴリー font/Illustrator
2024年5月30日AcrobatProで埋め込まれたフォントの構造を確認するまいどおなじみTenです。つい先日まで自治会の会長さんというやつをやっていたのですけど、ドキュメントの整備や広報の配布作... カテゴリー Acrobat/font/PDF
2022年9月19日OTFフォントの持つヒント情報について週末はネットワークケーブル総延長300メートルほどを粛清した次第です。かしめたRJ45が40個ほどということで疲れました... カテゴリー font Comments: 0
2022年9月3日CFF2で廃止されたオペレータと代替取得方法えーと、暑いんだか涼しいんだかよくわからない昨今ですが、いかがお過ごしでしょうか。 最近少し忙しくなってきたので、疲れま... カテゴリー font Comments: 0
2017年7月25日SVGフォントを作ってみよう。盛夏の候 皆様におかれましてはご清祥の事とお慶び申し上げます。クソ暑くってやんなっちゃいますけど、みなさん、元気してます... カテゴリー font Comments: 0
2017年2月21日Apple Color Emojiフォントを見本になにかする その2後回しにしたチェックサムの件… OTFフォントのチェックサムというのはとても面白い仕組みです。基本的に32bitの符号な... カテゴリー Uncategorized Comments: 0
2017年2月16日Apple Color Emojiフォントを見本になにかする その1何気なくつぶやいたら思いの外反響のあった絵文字フォントの件なのですが、一足飛びにsbixだけを解説してお茶を濁すのも面白... カテゴリー 未分類 Comments: 0
2012年8月24日Main routin色々とやっているわけですが、フォントのマッピングテーブルってかなり大きいんです。そりゃそうです。Romanなフォントはと... カテゴリー 未分類 Comments: 0
2012年7月18日ばらばらにしませう…突然梅雨が明けて酷暑が続いております。みなさん体調管理には充分ご注意下さい。わたしも先日プールに行ってきたのですが、曇っ... カテゴリー etc Comments: 0
2012年7月9日Opentypeフォントの構造先日、むすめとしまじろうを見に行ってきました。トリッピーが予想以上に丸っこくて、足元見えないよねぇ〜なんて思ってましたが... カテゴリー Uncategorized Comments: 0